コネクタープライベートネットワーキングの紹介 : 今後のウェビナーに参加しましょう!
It's Okay To Store Data In Kafka
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
A question people often ask about Apache Kafka® is whether it is okay to use it for longer term storage. Kafka, as you might know, stores a log of records, something like this:
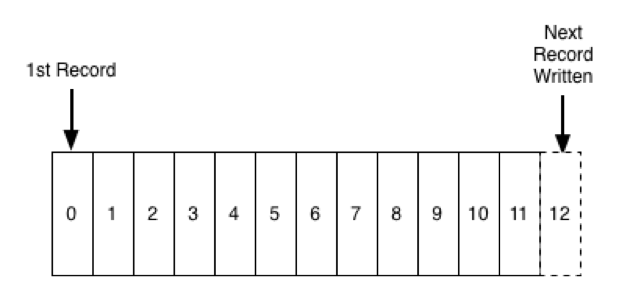
The question is whether you can treat this log like a file and use it as the source-of-truth store for your data.
Obviously this is possible, if you just set the retention to “forever” or enable log compaction on a topic, then data will be kept for all time. But I think the question people are really asking, is less whether this will work, and more whether it is something that is totally insane to do.
The short answer is that it’s not insane, people do this all the time, and Kafka was actually designed for this type of usage. But first, why might you want to do this? There are actually a number of use cases, here’s a few:
- You may be building an application using event sourcing and need a store for the log of changes. Theoretically you could use any system to store this log, but Kafka directly solves a lot of the problems of an immutable log and “materialized views” computed off of that. The New York Times does this for all their article data as the heart of their CMS.
- You may have an in-memory cache in each instance of your application that is fed by updates from Kafka. A very simple way of building this is to make the Kafka topic log compacted, and have the app simply start fresh at offset zero whenever it restarts to populate its cache.
- Stream processing jobs do computation off a stream of data coming via Kafka. When the logic of the stream processing code changes, you often want to recompute your results. A very simple way to do this is just to reset the offset for the program to zero to recompute the results with the new code. This sometimes goes by the somewhat grandiose name of The Kappa Architecture.
- Kafka is often used to capture and distribute a stream of database updates (this is often called Change Data Capture or CDC). Applications that consume this data in steady state just need the newest changes, however new applications need start with a full dump or snapshot of data. However performing a full dump of a large production database is often a very delicate and time consuming operation. Enabling log compaction on the topic containing the stream of changes allows consumers of this data to simple reload by resetting to offset zero.
So is it crazy to do this? The answer is no, there’s nothing crazy about storing data in Kafka: it works well for this because it was designed to do it. Data in Kafka is persisted to disk, checksummed, and replicated for fault tolerance. Accumulating more stored data doesn’t make it slower. There are Kafka clusters running in production with over a petabyte of stored data.
So why does storing data in Kafka cause people so much concern given that it is so obviously built like a storage system?
I think the natural concerns that people have comes from Kafka often being described as a messaging queue. The first two rules of message queues are “you do not store messages in the message queue.” There are a bunch of reasons this doesn’t work in a traditional messaging system:
- Because reading the message also removes it
- Because messaging systems scale poorly as data accumulates beyond what fits in memory.
- Because messaging systems generally lack robust replication features (so if the broker dies, your data may well be gone too).
These are actually big weaknesses in the design of traditional messaging systems. After all, if you think about it, any asynchronous messaging is fundamentally about storing messages, even if it is just for a few seconds until they are consumed. After all, if my service sends a message to some queue and proceeds with its business, yet I want some guarantee that your service will eventually receive and process that message, then something somewhere must store it until your service can do so. So if your messaging system is not good at storing messages then it isn’t good at “queuing” messages either. You might think that this doesn’t matter because you don’t plan on storing messages for very long. But no matter how briefly messages are stored in the messaging system, if the messaging system is under continuous load, there will always be some unconsumed messages being stored. So whenever it does fail, if it has no capability of providing fault tolerant storage, it is going to lose some data. Doing messaging right requires getting storage right. This point seems obvious but is often missed when people evaluate messaging systems.
So storage is important for messaging use cases. But in fact, Kafka isn’t really a message queue in the traditional sense at all—in implementation it looks nothing like RabbitMQ or other similar technologies. It is much closer in architecture to a distributed filesystem or database then to traditional message queue. There are three primary differences between Kafka and traditional messaging systems:
- As we described, Kafka stores a persistent log which can be re-read and kept indefinitely.
- Kafka is built as a modern distributed system: it’s runs as a cluster, can expand or contract elastically, and replicates data internally for fault-tolerance and high-availability.
- Kafka is built to allow real-time stream processing, not just processing of a single message at a time. This allows working with data streams at a much higher level of abstraction.
We think of these differences as being enough to make it pretty inaccurate to think of Kafka as a message queue, and instead categorize it as a Streaming Platform.
One way to think about the relationship between messaging systems, storage systems, and Kafka is the following. Messaging systems are all about propagating future messages: when you connect to one you are waiting for new messages to arrive. Storage systems such as a filesystem or a database are all about storing past writes: when you query or read from them you get results based on the updates you did in the past. The essence of stream processing is being able to combine these two—being able to process from the past, and continue processing into the future as the future occurs. This is why Kafka’s core abstraction is a continuous time-ordered log. The key to this abstraction is that it is a kind of structured “file” that doesn’t end when you come to the last byte, but rather, at least logically, goes on forever. A program written to work with a log therefore doesn’t need to differentiate between data that already occurred and data that is going to happen in the future, it all appears as one continuous stream. This combination of storing the past and propagating the future behind a single uniform protocol and API is exactly what makes Kafka work well for stream processing.
This stored log is very much like a file in a distributed file system in that it is replicated across machines, persisted to disk, and supports high-throughput linear reads and writes, but it is also like a messaging system in that it allows many, many high-throughput concurrent writes and has a very precise definition of when a message is published to allow cheap, low-latency propagation of changes to lots of consumers. In this sense it is the best of both worlds.
In implementation, this replicated log is perfectly well suited for use as storage, and that isn’t an accident. In fact, Kafka uses itself as storage, so you can’t avoid it! Internally Kafka stores the offsets that track consumers’ positions in a compacted Kafka topic, and Kafka’s Streams API uses compacted topics as the journal for your application’s processing state. Both of these use cases require permanent storage of the data that is written.
Treating Kafka as a primary store does mean raising the bar for how you run it, though. Storage systems rightly have a huge burden in terms of correctness, uptime, and data integrity. I was involved in building and running several generations of distributed database at LinkedIn, and when a system is treated as the canonical source for data the bar for both software correctness and operational practices increases quite dramatically. We’ve put a lot of effort into correctness for Kafka—we run hundreds of machine hours of distributed torture tests on it every day in addition to thousands of normal unit tests—but there is honestly always more to do. But beyond testing, if you’re running Kafka for this kind of use case, you need to make sure you know how to operate it well, and you need to know the limitation the system has.
This is something where Confluent can help: we offer support and tools for running managing and monitoring Kafka yourself, or a hosted service so you don’t have to.
When I talk about this with other people they sometimes ask if this means Kafka could become a kind of universal database, obsoleting all other storage thingies (obviously I talk to a lot of Kafka fans). The answer is probably not, for two reasons:
First, databases are mostly about queries, and I don’t think Kafka really benefits from trying to add any kind of random access lookups directly against the log. Rather what it is doing is storing a log of the data that can be replicated into any number of databases, caches, stream processors, search thingies, graph stores, and data lakes (not to mention custom applications or SaaS products). Each of these systems have their own pros and cons, and I think it’s hubris to think you can do better than all of them in a single system. These stores typically need to be very very closely tied to their own storage layout (e.g. analytical database have very sophisticated columnar indexing techniques, search indexes keep inverted indexes, caches are in memory, LSMs are good at writes, btrees good at reads, etc).
If Kafka isn’t going to be a universal format for queries, what is it? I think it makes more sense to think of your datacenter as a giant database, in that database Kafka is the commit log, and these various storage systems are kinds of derived indexes or views. It’s true that a log like Kafka can be fantastic primitive for building a database, but the queries are still served out of indexes that were built for the appropriate access pattern.
One of the best examples of this is the interactive queries feature in Kafka’s Streams API. Processing in Kafka Streams apps are just another Kafka consumer, but they can maintain computed state they materialize off the stream. This state can be queried directly or piped out into external systems. This doesn’t involve querying Kafka directly at all, but rather makes it so that stream processing applications can, keep a derived, queryable, materialized view of the data in Kafka and run low latency queries against it. The Kafka cluster stores the log, and the stream processing API stores the materialized view and processes queries against it. You can think of this as a kind of refactoring of the dividing line between the application and the database. This becomes even more interesting as we add KSQL to the picture, a streaming SQL engine for Kafka. With KSQL, you no longer need to write any code but can use SQL statements to continuously transform and compute materialized views off of Kafka (and soon to do queries against those views).
But perhaps another reason Kafka isn’t adding query APIs is that it has a more exciting mission. Our goal with Kafka is to make streams of data and stream processing a mainstream development paradigm and make this type of streaming platform something that acts as a central nervous system for a modern digital business. I think this is actually a much more interesting than building the 1001st database. I think this type of streaming platform is going to be essential to how data moves and is processed in a modern enterprise, and how modern real-time applications are built. There is a ton of work to do to make this a reality. So we’re focusing on that first.
Interested in more?
If you’re looking for the fastest way to run Apache Kafka, you can sign up for fully managed Apache Kafka as a service with Confluent Cloud and receive $400 of free usage during your first 60 days, plus an additional $60 of free usage when you use the promo code CL60BLOG.*
Get started with Confluent, for free
Watch demo: Kafka streaming in 10 minutes
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Kafka-docker-composer: A Simple Tool to Create a docker-compose.yml File for Failover Testing
The Kafka-Docker-composer is a simple tool to create a docker-compose.yml file for failover testing, to understand cluster settings like Kraft, and for the development of applications and connectors.


How to Process GitHub Data with Kafka Streams
Learn how to track events in a large codebase, GitHub in this example, using Apache Kafka and Kafka Streams.